

Potser els detectors d’IA no detecten IA
Quan se m'acut fer quelcom interessant amb IA i català

Durant mesos, internet s’ha omplert de detectors d’intel·ligència artificial. Plataformes amb noms solemnes, percentatges vermells i promeses gairebé místiques: “aquest text ha estat escrit per una IA”. El problema és que, després de provar-ne uns quants amb calma, la sensació és estranya. Massa estranya.
Textos humans detectats com a artificials. Documents acadèmics marcats com si haguessin sortit directament d’un laboratori de Silicon Valley. Articles periodístics classificats amb percentatges d’IA ridículament elevats. I, paral·lelament, textos generats amb models avançats passant relativament desapercebuts.
Hi havia alguna cosa que no quadrava.
Així que vaig decidir fer una prova senzilla: entrenar un detector específic per català i observar què passava realment.
No per construir una màquina de caça de tramposos universitaris. No per jugar a policies lingüístics. Sinó per entendre què és exactament el que aquests sistemes detecten.
I la conclusió a la qual he arribat és molt més inquietant del que esperava.
Potser els detectors actuals no detecten IA.
Potser detecten llenguatge industrialitzat.
El model
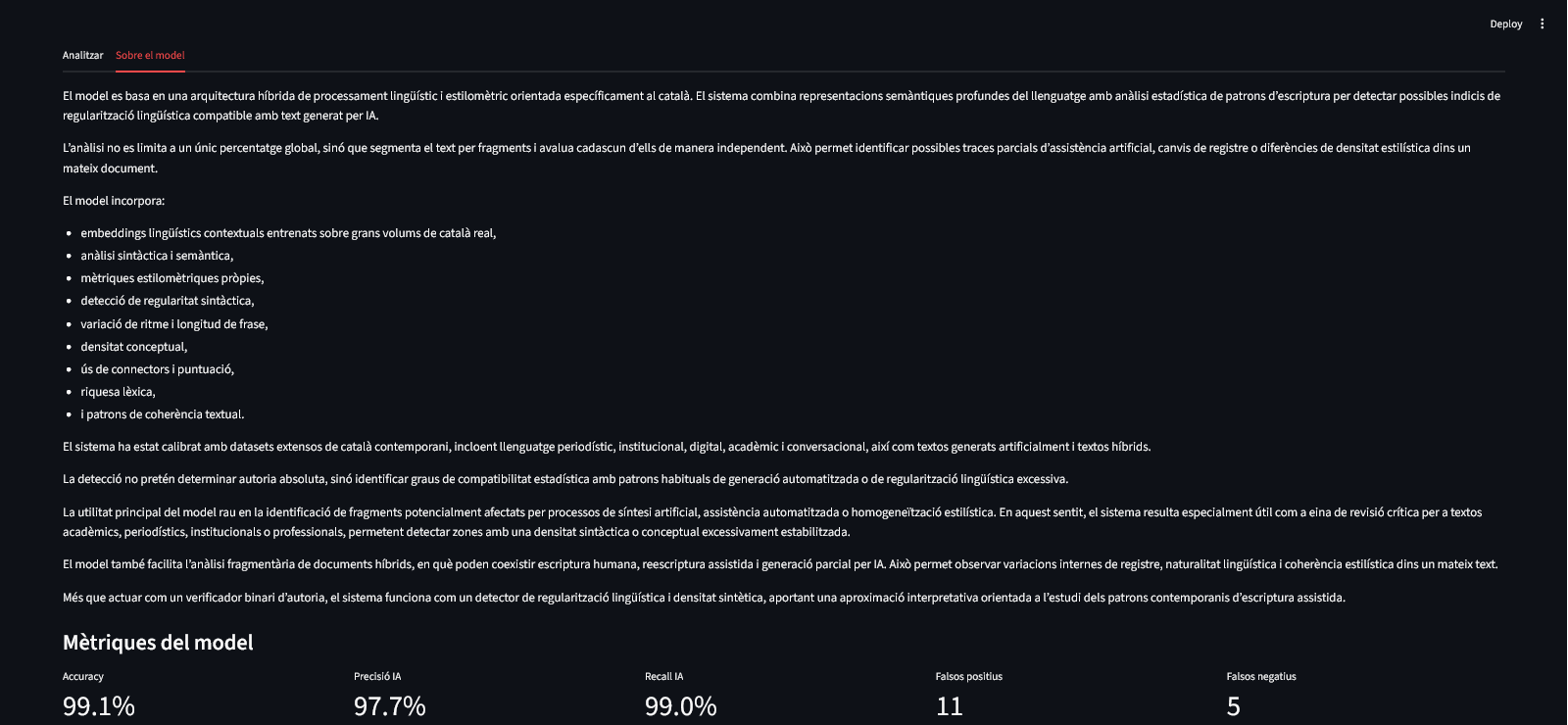
El sistema desenvolupat funciona sobre una arquitectura híbrida de processament lingüístic i estilomètric orientada específicament al català. El model combina representacions semàntiques profundes del llenguatge amb anàlisi estadística de patrons d’escriptura per detectar possibles indicis de regularització lingüística compatible amb generació assistida per IA.
L’anàlisi no es limita a un únic percentatge global, sinó que segmenta el text per fragments i avalua cadascun d’ells de manera independent. Això permet identificar traces parcials, canvis de registre o diferències de densitat estilística dins un mateix document.
El sistema incorpora:
embeddings lingüístics contextuals,
anàlisi sintàctica i semàntica,
mètriques estilomètriques pròpies,
detecció de regularitat sintàctica,
variació de ritme i longitud de frase,
densitat conceptual,
ús de connectors i puntuació,
riquesa lèxica,
i patrons de coherència textual.
Les proves internes del model mostren:
Accuracy: 99.1%
Precisió IA: 97.7%
Recall IA: 99%
Falsos positius: 11
Falsos negatius: 5
El problema del “text perfecte”
El model no funciona com un oracle binari que decideix si un text és humà o artificial. De fet, una de les primeres decisions va ser evitar precisament això.
El sistema treballa fragment per fragment. Detecta gradients. Dubta. Marca “traça IA”, “possible IA”, “humà” o “IA” segons patrons lingüístics i estilomètrics observats dins el text.
No busca “paraules prohibides”. Analitza regularització.
És a dir:
estabilitat sintàctica,
simetria excessiva,
tancaments massa perfectes,
densitat conceptual homogènia,
ritme constant,
i estructures discursives excessivament netes.
I aquí va aparèixer el primer descobriment interessant: el detector no reaccionava especialment al “text ben escrit”. Reaccionava al text excessivament estabilitzat.
Això incloïa:
documents corporatius,
llenguatge institucional,
fragments acadèmics molt polits,
periodisme industrial,
i, evidentment, molts textos generats per IA.
La coincidència era inquietant.
Quan el periodisme sona com ChatGPT
Una de les proves més curioses va arribar analitzant un article real d’El Periódico sobre els mercats de Barcelona i l’augment de parades buides.
El comportament del detector va resultar especialment revelador.
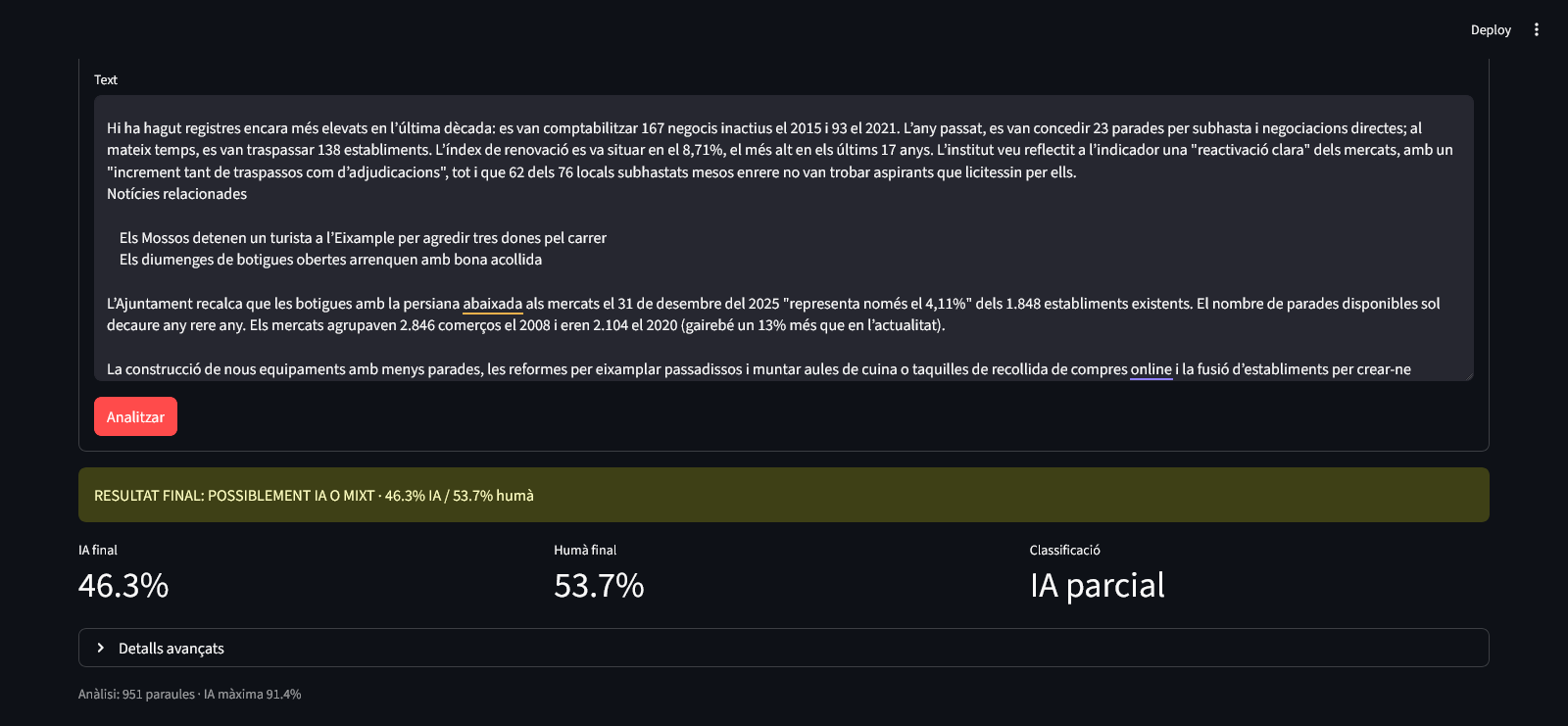
Les parts més factuals, contextuals o descriptives acostumaven a aparèixer en verd. En canvi, els titulars condensats, les síntesis perfectes i les frases excessivament empaquetades conceptualment pujaven ràpidament cap al vermell.
No perquè fossin generades artificialment.
Sinó perquè sonaven exactament com el tipus de llenguatge que els models generatius han après a imitar.
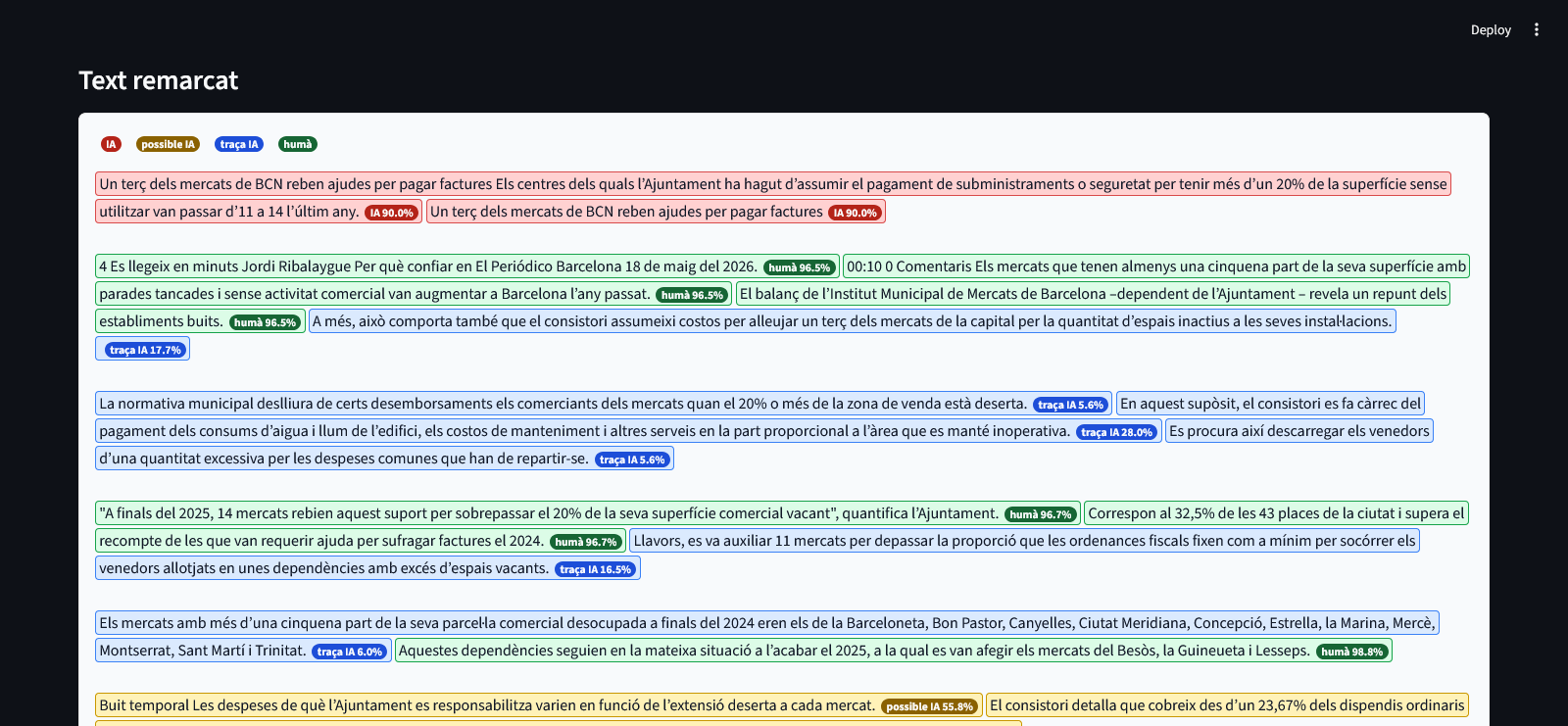
I aquí apareix una idea incòmoda.
Potser els LLMs no han inventat aquest estil.
Potser només han après el llenguatge que ja dominava internet, les institucions, les empreses, el SEO, l’acadèmia i bona part dels mitjans digitals. I després l’han maximitzat fins al límit.
El resultat és fascinant: alguns detectors no semblen distingir humans de màquines. Semblen distingir llenguatge viu de llenguatge excessivament regularitzat.
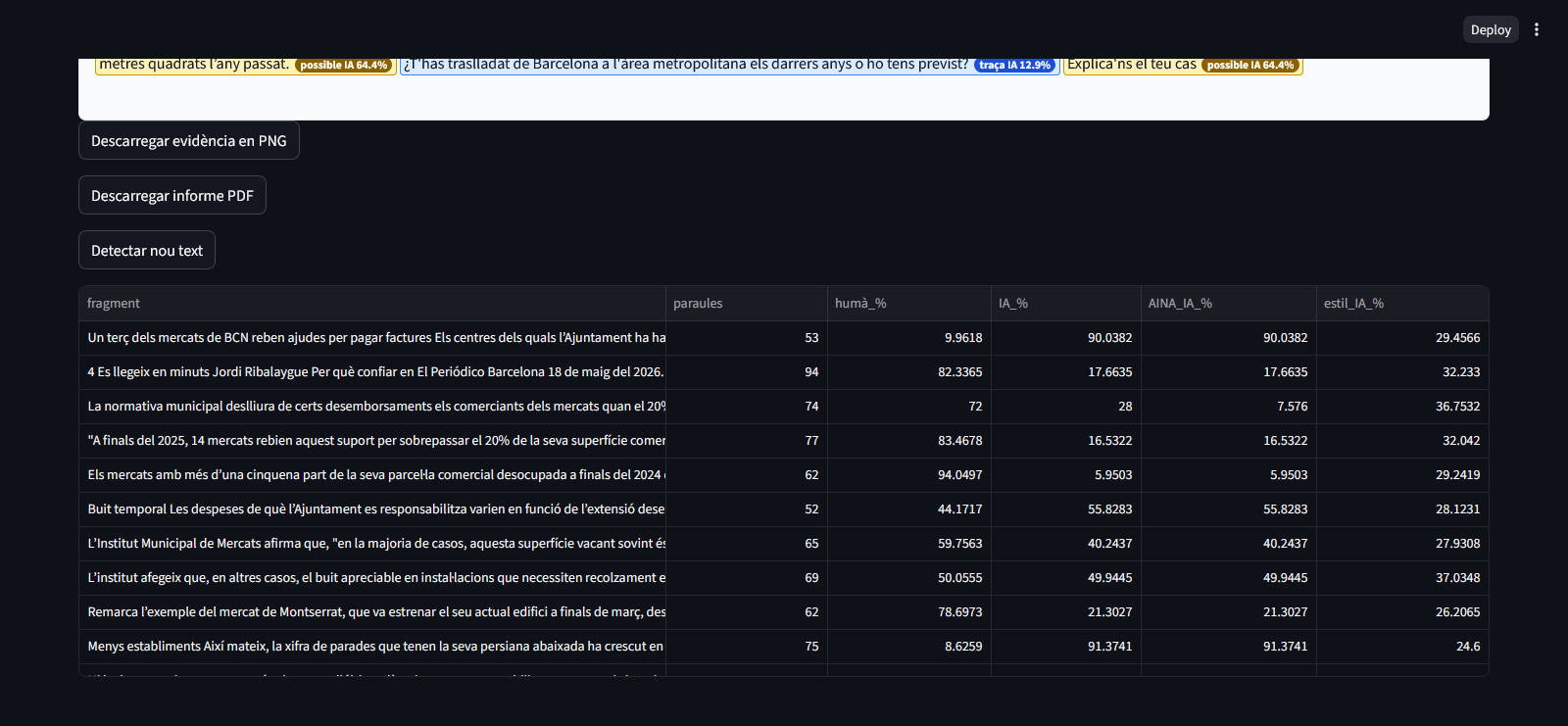
Les evidències
El sistema genera:
informes PDF,
captures exportables,
i anàlisi fragmentària detallada.
Això permet revisar:
quins fragments han estat marcats,
quin tipus de regularització s’ha detectat,
i com varia la classificació dins un mateix document.
També incorpora mètriques internes i taules avançades per analitzar:
percentatges IA/humà,
estil IA,
longitud fragmentària,
i densitat sintètica.
El català com a camp de proves
Una de les limitacions més evidents dels detectors comercials és el català. Molts sistemes globals funcionen relativament bé en anglès, però quan entren en llengües minoritzades comencen els problemes.
Textos humans marcats com a IA simplement per ser formals. Assajos acadèmics tractats com si fossin outputs sintètics. Articles d’opinió detectats com a artificials només perquè tenen coherència.
Això passa perquè molts detectors no entenen realment el català. Generalitzen patrons entrenats principalment sobre anglès.
Per això el model es va entrenar sobre grans volums de català contemporani:
llenguatge periodístic,
institucional,
conversacional,
digital,
acadèmic,
i també textos generats artificialment.
El resultat no és un “detector infal·lible”. Això no existeix.
Però sí una eina sorprenentment útil per observar una cosa molt concreta: la densitat sintètica d’un text.
El descobriment accidental
Després de moltes proves, hi ha una conclusió que em costa ignorar.
El model funciona millor quan no intenta detectar “IA”.
Funciona millor quan detecta regularització lingüística.
I això canvia completament la conversa.
Perquè avui el problema no és només que les màquines escriguin com humans. El problema és que una part enorme del llenguatge humà ja havia començat a sonar com una màquina abans de l’arribada massiva dels LLMs.
Discurs corporatiu.
SEO.
Institucionalització del llenguatge.
Acadèmia hiperpolida.
Periodisme optimitzat per clics i síntesi constant.
Els models generatius no han creat aquest ecosistema.
L’han absorbit.
I després l’han reproduït amb una eficiència monstruosa.
El futur dels detectors
Potser el futur no consistirà a distingir humans de màquines.
Potser consistirà a detectar fins a quin punt un text conserva irregularitat humana.
Ritme variable.
Tensió.
Desordre controlat.
Veu pròpia.
Respiració lingüística.
Tot allò que la producció massiva de llenguatge tendeix a eliminar.
Per això el projecte no s’ha plantejat mai com un jutge d’autoria absoluta. El mateix sistema ho deixa clar des del principi:
“Aquest sistema no determina autoria de manera absoluta. Detecta patrons lingüístics compatibles amb generació, assistència o regularització per IA.”
I sincerament? Crec que és una aproximació molt més honesta que la majoria de detectors que prometen màgia estadística.
Perquè potser la pregunta correcta no és:
“això ho ha escrit una IA?”
Potser la pregunta real és:
“quan vam començar tots a escriure igual?”